Adapting to Varied Camera-Person Relationships
Tunnel Try-on can not only handle complex clothing and backgrounds but also adapt to different types of movements in the video.
Person-to-Camera Distance Variation
Parallel Motion Relative to the Camera
Camera Angle Dynamics
Adapting to Different Clothing Styles
Unlike previous video try-on methods limited to fitting tight-fitting tops, Our Tunnel Try-on can perform try-on tasks for different types of tops and bottoms.
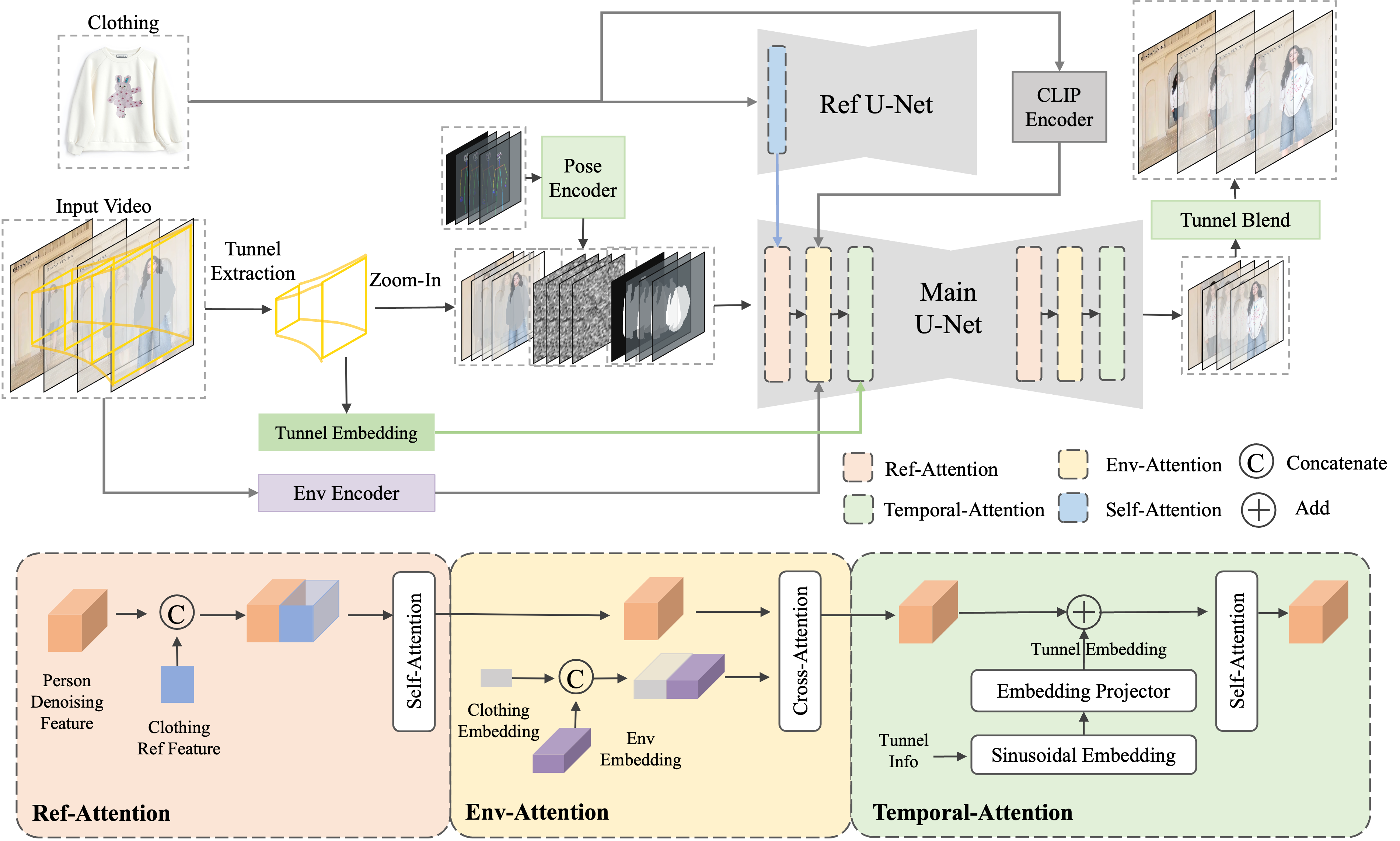
Framework
Given an input video and a clothing image, Tunnel Try-on first extracts a focus tunnel to zoom in on the region around the garments to better preserve the details. The zoomed region is represented by a sequence of tensors consisting of the background latent, latent noise, and the garment mask. Human pose information is added to the latent noise to assist the generation. Afterward, the 9-channel tensor is fed into the Main U-Net while a Ref U-Net and a CLIP Encoder are used to extract the representations of the clothing image, the clothing representations are added to the Main U-Net with the ref-attention. At the same time, Tunnel Try-on utilizes the tunnel embedding into temporal attention to generate more consistent motions and develop an environment encoder to extract the global context as additional guidance.
BibTeX
@article{xu2024tunnel,
title={Tunnel Try-on: Excavating Spatial-temporal Tunnels for High-quality Virtual Try-on in Videos},
author={Xu, Zhengze and Chen, Mengting and Wang, Zhao and Xing, Linyu and Zhai, Zhonghua and Sang, Nong and Lan, Jinsong and Xiao, Shuai and Gao, Changxin},
journal={arXiv preprint arXiv:2404.17571},
year={2024}
}